1. Intro
- 중단을 가능한 짧게가져가고 전환하고싶었다
- 운영 클러스터는 그대로 동작하고 별도의 작업클러스터로 장애전달가능성 줄이기
- snapshot을 얼마나 신뢰할 수 있는가
- snapshot 시작시점의 정합성? 종료시점의 정합성?
- 검증을 어느정도로 빡세게 해야하는가
- 무중단 전환을 위해서는 앱과 DB 클러스터간의 별도의 레이어 필요
2. Syncronization Overview
main cluster > target Server – X
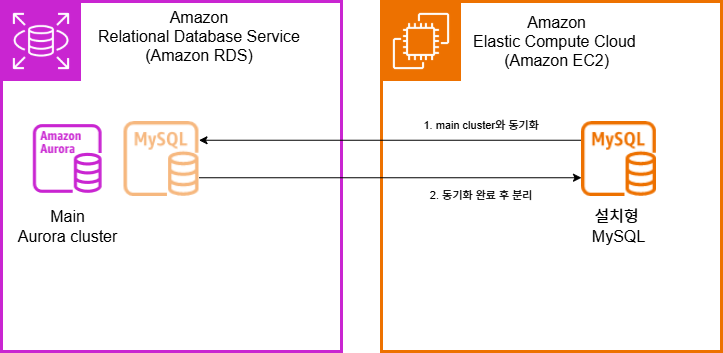
main RDS 클러스터에, 타겟 MySQL 서버를 추가시켜 필요한 데이터들을 복제 및 동기화하고 클러스터에서 분리하려는 초기의 계획은 버전 이슈로인해 원활히 작동 X
- collation set
- system table의 database engine: MyISAM
main cluster > replica cluster > MySQL Server (instance)
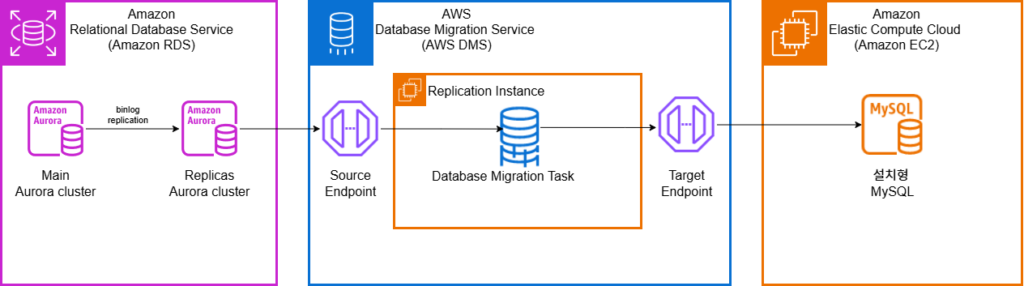
CDC (AWS DMS)를 사용해서, 클러스터의 운영에 필요한 테이블들은 제외하고, 실제 데이터가 생성되고 갱신되는 테이블만 가져와 동기화하도록 구성할 수 있다.
3. Aurora cluster 간 동기화(main-replica)
스냅샷 복제를 통해 RDS 클러스터의 특정시점을 지정하여 별도의 클러스터로 복제(재생성)할 수 있다. 생성된 클러스터는 완전히 분리된 별개의 클러스터로 생성된다
해당 경우 클러스터간의 동기화를 위해 두 RDS 클러스터간에 binlog 기반 복제를 설정할 수 있다. 그러한 경우 main 클러스터의 binlog position을 확인 한 뒤, Replica DB에서 M의 바이너리 로그를 읽어와 R의 릴레이 로그에서 재생함으로써 논리적인 데이터 복제를 수행할 수 있다.
해당 과정을 위해 설정해야하는 과정은 위의 AWS 문서와 같다. 정리 및 공유차 step별 수행단계만 재정리
- Source) Aurora MySQL
- Target) Aurora MySQL
- Source) Binlog 활성화
- 바이너리 로그 기반 복제인 만큼 binlog를 활성화해야함
- DB 클러스터 파라미터 그룹에서
binlog_format변경- default OFF > ROW 등으로 변경
- 변경이후 클러스터 재시작 필요
- Source) binlog 저장 주기 연장
- Replica에서 릴레이 받아갈 원본 로그의 저장 주기
- default NULL 로 설정되어있음 > 필요시 연장 (최대 90일)
- CALL mysql.rds_show_configuration; (현재 값보기)
- CALL mysql.rds_set_configuration(‘binlog retention hours’, 144)
- (6일간 보관으로 설정)
- Source) 스냅샷 생성 및 복원
- 특정시점으로 고정하기 위해 스냅샷을 생성 한 뒤, 해당 스냅샷 기반으로 작업
- 수동으로 생성 또는 자동 생성된 스냅샷 활용 가능
- 유지 관리 및 백업 > 스냅샷 복원
- 복원시 기존 Source와 동일한 DB 클러스터/ DB 인스턴스 파라미터 체크
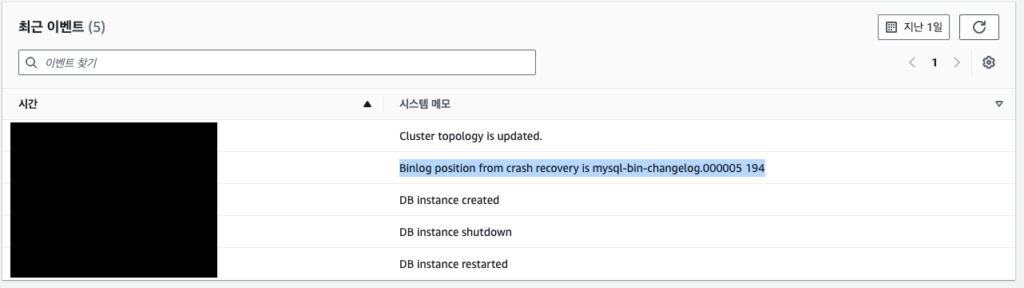
- Replica) 생성된 복제 클러스터의 binlog file/pos 체크
- 로그 및 이벤트 > 최근 이벤트
- Replica) 생성된 복제 클러스터에서 mysqldump (선택)
- 상황에 따라 미리 사전에 mysqldump로 사본 생성 뒤 전달 권장
- dump 생성 후 압축 or 암호화로 전달 효율화
- 실 운영중인 source clster와 분리된 replica cluster 이기에 테이블 lock이나 부하 걱정 필요 X
- 상황에 따라 미리 사전에 mysqldump로 사본 생성 뒤 전달 권장
- Source) 복제작업용 계정생성
- skip_name_resolve 주의할것
- aurora instance의 DNS (main-instance-1.ctggy8qyy8gq.ap-northeast-2.rds.amazonaws.com) 를 그대로 사용하면 ndot 이슈인지? 그대로 설정X
- nslookup을 통해 직접 인스턴스 IP or testdb.logonme.click 등과같이 DNS등을 지정
- Replica) Source 연결용 계정을 사용해 원본의 데이터 이전
- CALL mysql.rds_set_external_master (‘ testdb.logonme.click’, 3306,’repl_user’, ‘password’, ‘mysql-bin-changelog.000005’, 194, 0);
3.1. Snapshot 정합성?
AWS RDS 스냅샷 생성시,
생성 시작 – 생성 완료 사이의 상태가 저장됨
RDS snapshot 생성 및 복원시, 어느시점까지의 데이터가 복원되는가?
- 스냅샷 생성 시작 시점의 정보?
- 스냅샷 생성 완료 시점의 정보?
별도의 테이블을 생성하여, 10초에 한번씩 insert 하는 스크립트를 실행한 상태로 스냅샷 생성 및 복원을 하면 생성 시작 시점과 생성 완료사이의 특정 시점까지만 저장되었다.
일반적인 mysqldump처럼 각 테이블별로 순차적으로 dump뜨는 동작이 아닌가 하는 생각중
dummy-insert.sh
- dummy database 생성
-- 더미 데이터베이스 생성
CREATE DATABASE dummy_db;
-- 더미 데이터베이스 사용
USE dummy_db;
-- 테이블 생성
CREATE TABLE dummy_table (
id INT AUTO_INCREMENT PRIMARY KEY,
created_at DATETIME DEFAULT CURRENT_TIMESTAMP
);- 10초에 한번 Insert
#!/bin/sh
DB_HOST="testdb.logonme.clickz"
DB_USER="repl_user"
DB_PORT="3306"
DB_PASS="password"
while true; do
mysql -h $DB_HOST -u $DB_USER -p$DB_PASS $DB_NAME -e "INSERT INTO dummy_db.dummy_table (created_at) VALUES (NOW());"
echo "Inserted row at $(date)"
sleep 10
done- 스냅샷 복원 시작
- 11시 32분 > 스냅샷 생성 시작
- 11시 36분 > 스냅샷 생성 완료
- 11시 41분 > 스냅샷 복원 RDS 클러스터 시작

- 복원된 클러스터의 데이터 조회
- -e “SELECT * FROM dummy_db.dummy_table ORDER BY id DESC LIMIT 10;”
- 복원된 클러스터에는 11시 34분즈음 까지의 데이터만 남아있음

- 스냅샷 생성시작에 모든 table에 lock이 걸렸다면, 11:32의 기록만이 남아있어야함
- 스냅샷 종료시점까지의 정보라면, 일부 누락이 있을수 있음
- 해당테이블이 덤프된 34분부터, 스냅샷 완료인 36분간의 데이터 유실 가능성
3.2 Replication 확인
AWS RDS 클러스터간 Binlog 동기화를 설정하면 데이터 싱크 유지됨
RDS 원본 클러스터와, 스냅샷에 기반한 복제 클러스터간의 binlog 동기화를 설정하면 동종 MySQL간의 복제이므로 원활히 적당하고, 희망 수준의 동기화를 이룰 수 있었음.
- 스냅샷 클러스터에서
SHOW SLAVE STATUS\G등을 통해 동기화 상황 조회 가능 - Slave_IO_state, Slave_SQL_Running_State, Seconds_Behind_Master(=0) 등의 값을 통해 동기화 여부 확인 가능
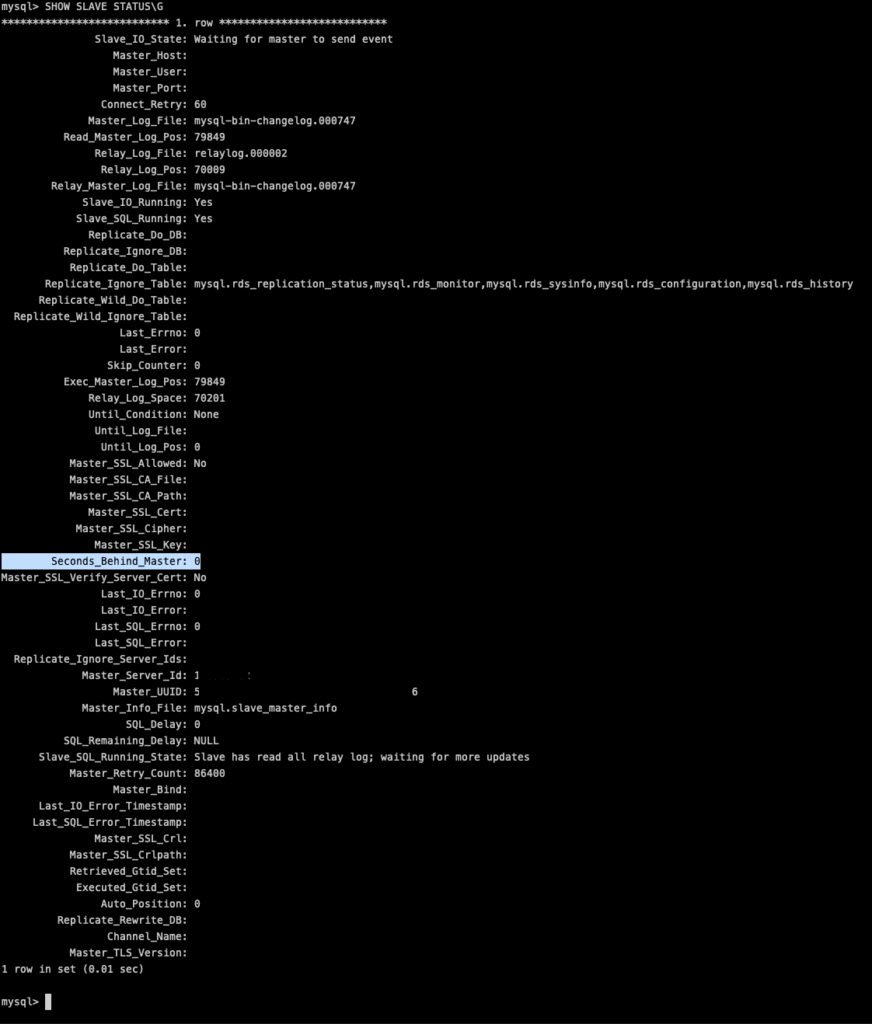
Master 클러스터의 binary logs를, Slave 클러스터가 읽고 Slave의 Relay logs로 변경을 수행해 상태 동기화를 이룬다.
slave에서 실질적으로 어떤 쿼리문들이 수행되는지 확인하려면, 위의 쿼리문을 통해 조회되는 결과 중 Master logs, relay logs 파일/포지션을 확인한 뒤 바이너리 형식으로 저장된 로그를 mysqlbinlog 명령어를 사용해 텍스트 형식으로 변경해 확인할 수 있다. 해당 과정은 이번글에서는 다루지 않고 관련 참고자료등 참고바람
4. Replica RDS > MySQL로 데이터 전달 (DMS)
https://docs.aws.amazon.com/ko_kr/dms/latest/userguide/Welcome.html
DMS는 Database Migration Service의 줄임말
특정 DB에서 다른 DB로 데이터를 전달하는 기능을 수행한다
이전의 replication 시도시 system table들로 인해 연결이 불가능했다
> 이전이 필요한 스키마/테이블만 잡아서 전달하면 되지않을까
보편적으로 이러한 목적성을 가진 기능들은 CDC(capture data change)라는 키워드로 구현방식/사용사례들을 찾아 볼 수 있다. 연관 오픈소스로 kafka debezium, flink 등 CDC 도구들이 있고 MySQL to MySQL 같은 동종간 데이터 전달 뿐만아니라, MySQL to MongoDB등 이종간 데이터 전달 또한 수행할 수 있다. 본 블로그 글에서는 AWS에서 제공하는 CDC 툴인 DMS를 사용해 replica cluster의 변경분만을 캡쳐해, target database로 전달하도록 구성하였다
1. endpoint 설정
- Source endpoint 설정 (RDS instance)
- Target endpoint 설정 (EC2 or IDC Server)
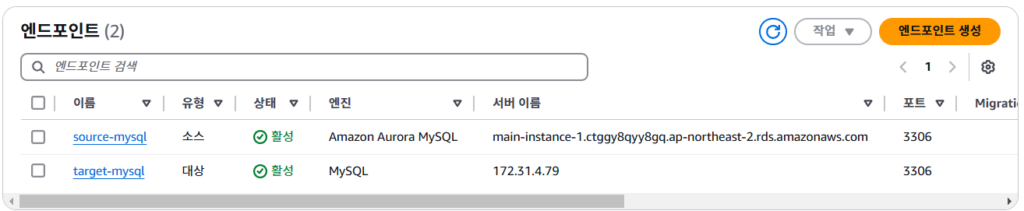
2. 복제 인스턴스 생성
- 두 엔드포인트 사이에서 복제 및 전달할 컴퓨팅 리소스(EC2)
- 두 엔드포인트에 접근할수 있는 네트워크대역에 생성 필요 (방화벽 or 보안그룹 허가)
- 실제 작업 필요량에 따라 적절한 spec 산정 필요

3. Database Migration Task 생성
- Source endpoint에서, Target endpoint로 어떤 변경을 감지하여 전송할지 설정
- 복제 유형
- 마이그레이션 > 전체 내용을 다 옮길것인지
- 일반적인 CDC에서의 스냅샷 단계
- 복제 > 특정 시점이후로 캡쳐된 데이터만 옮길것인지
- 일반적인 CDC에서의 데이터 전송 단계
- 원본 데이터가 많을수록, 스냅샷 단계를 CDC를 통해 수행하기 보다는 별도의 dump등을 통해 전송한 뒤 복제 활성화를 권장
- data외의 메타데이터등의 정보 누락
- dump 생성 후 압축 등으로 스토리지/네트워크 트래픽 감소
- 압축된 dump에 암호화 설정등으로 전송간 보안 강화
- 마이그레이션 > 전체 내용을 다 옮길것인지
- 태스크 설정
- 어떤 변경점을 전달할지 ruleset 설정
- 선택된 데이터에 대해, 변경하여 전달하는 변환 규칙 또한 설정가능
이후 전달된 데이터들에 대한 작동 모니터링 등이 수행 가능하다
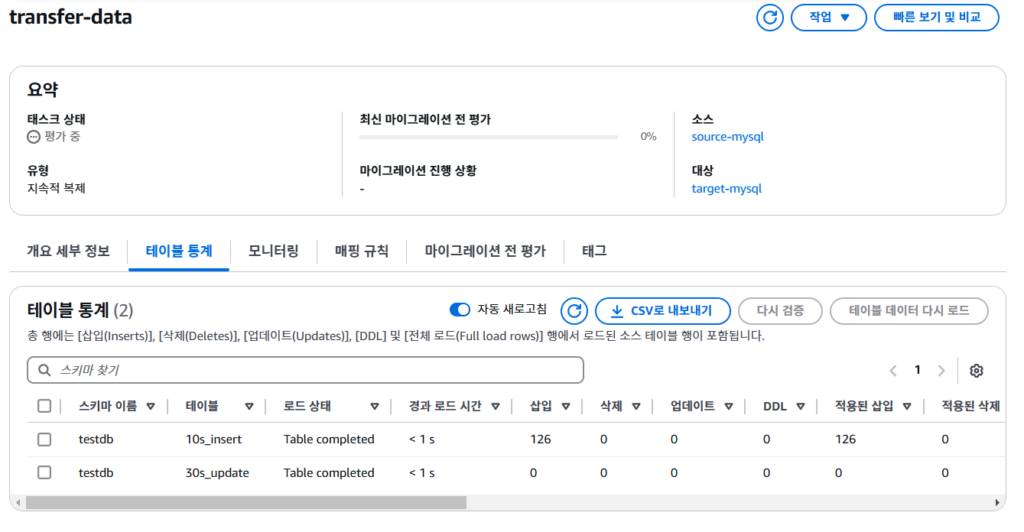
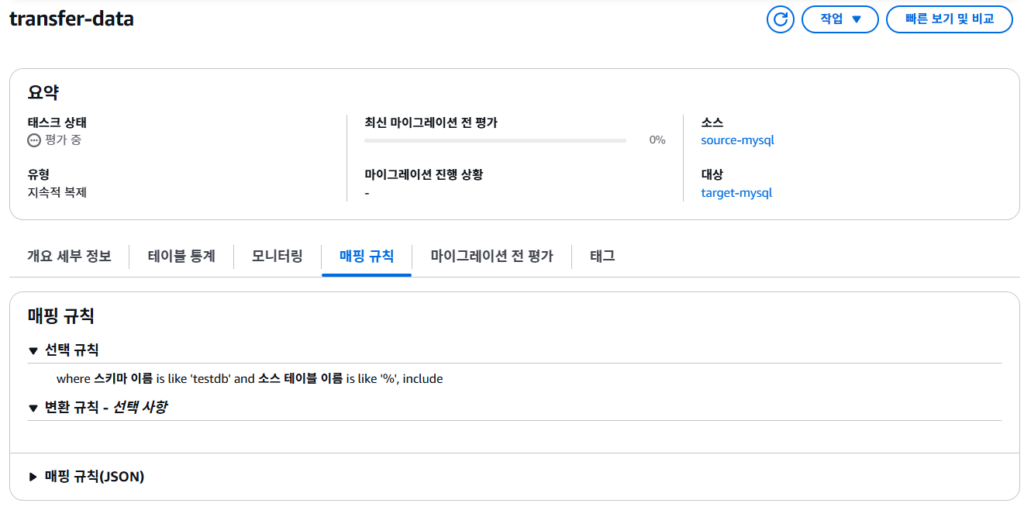
5. 실제 이관 작업
모든 구성요소의 동작을 확인한 뒤, 아래와 같은 순서를 통해 안정적인 데이터 이관을 확인할 수 있다.
- 특정 시점(UTC 자정)으로 생성된 snapshot을 통한 복제용 클러스터 생성
- 원본 클러스터와 복제 클러스터간 binlog 동기화 설정
- 원본<> 복제 간 binlog Replication 중단
- CALL mysql.rds_stop_replication;
- 복제 클러스터 대상 mysqldump 생성
- 생성된 덤프파일 압축 및 암호화등 수행 후 대상 클러스터로 전달 & 복원
- DMS task 생성 후 복제 <> 대상 간 작동 확인
- 원본 <> 복제 간 binlog Replicaion 재시작
- CALL mysql.rds_start_replication;
- 원본 <> 대상 간 동기화 확인
6. 데이터 검증
데이터 검증은 중요하다. 정합성이 중요한 Database인 이상 하나의 데이터라도 누락/변경이 된다면 전체 과정이 의미없기 때문이다
6.1. count 비교
테스트 중에는 단순히 count수로 차이가 없는지만 비교했다. INSERT 안됨등의 이슈를 빠르게 찾을 수 있다는 점에서는 좋으나, 실질적인 데이터 변화는 UPDATE 등이 수반되므로 실질적인 동기화가 보장되고 있음을 보장할 수 없다.
ex) encoding(emoji), default value와 null 값등의 구분 불가
#!/bin/sh
# nohup ./3-check-sync-countonly-noview.sh > main-replica-sync-count-noview.log 2>&1 &
M_DB_HOST="마스터 DNS"
M_DB_USER="마스터 user"
M_DB_PORT="마스터 port"
M_DB_PASS="마스터 pwd"
S_DB_HOST="슬레이브 DNS"
S_DB_USER="슬레이브 user"
S_DB_PORT="슬레이브 port"
S_DB_PASS="슬레이브 pwd"
# 시스템 테이블은 제외
M_DATABASES=(`MYSQL_PWD=$M_DB_PASS mysql -h$M_DB_HOST -u$M_DB_USER -e "show databases" | grep -v "Database\|information_schema\|mysql\|performance_schema\|sys"`)
# test를 위해 대상 테이블 직접 지정시
# M_DATABASES=(testdb111 testdb222)
DB_CNT=${#M_DATABASES[*]}
# 전체 시작 시간 기록
TOTAL_START_TIME=$(date +%s)
for ((i=0; i<$DB_CNT; i++)) ; do
DATABASE=${M_DATABASES[$i]}
# View table은 제외
TABLES=(`MYSQL_PWD=$M_DB_PASS mysql -h$M_DB_HOST -u$M_DB_USER -D$DATABASE -e "SHOW FULL TABLES WHERE Table_type='BASE TABLE'" | grep -v "Tables_in_"| awk '{print $1}'`)
# echo ${TABLES[*]}
TB_CNT=${#TABLES[*]}
for ((j=0; j<$TB_CNT; j++)) ; do
TABLE=${TABLES[$j]}
M_COUNTS=(`MYSQL_PWD=$M_DB_PASS mysql -h$M_DB_HOST -u$M_DB_USER -D$DATABASE -P$M_DB_PORT -e "SELECT COUNT(*) FROM $TABLE" | tail -n +2`)
S_COUNTS=(`MYSQL_PWD=$S_DB_PASS mysql -h$S_DB_HOST -u$S_DB_USER -D$DATABASE -P$S_DB_PORT -e "SELECT COUNT(*) FROM $TABLE" | tail -n +2`)
CT_CNT=${#M_COUNTS[*]}
for ((l=0; l<$CT_CNT; l++)) ; do
if [ "${M_COUNTS[$l]}" != "${S_COUNTS[$l]}" ] ; then
echo "$DATABASE.$TABLE COUNT diff: ${M_COUNTS[$l]} / ${S_COUNTS[$l]}"
else echo "M=S count okay for $DATABASE.$TABLE"
fi
done
done
done
TOTAL_END_TIME=$(date +%s)
TOTAL_SECOND=$((TOTAL_END_TIME - TOTAL_START_TIME))
TOTAL_MINUTE=$((TOTAL_SECOND / 60))
echo "-------"
echo "total took $TOTAL_SECOND sec / $TOTAL_MINUTE min"
6.2. Checksum 비교
MySQL 에서는 CHECKSUM TABLE [TABLES명]을 사용해 테이블 단위의 해시값을 생성한뒤, 원본과 사본에서의 체크섬 값을 비교하여 동일함 여부로 Database 테이블 간의 무결성을 확인할 수 있다.
아래 참고 링크의 스크립트 적절히 변경하여 활용
6.3. Row Data diff 비교
그러나 MySQL 5.7에서, JSON type의 Column의 경우 메모리 포인터가 지멋대로 작용해 실행시마다/세션마다 CHECKSUM 값이 달라지는 이슈가 있다
5.7 EOL 이후에 발견된 버그인지? 8.0에서는 해결되었지만 5.7에서는 업데이트 X
- https://bugs.mysql.com/bug.php?id=87847
- https://dev.mysql.com/doc/relnotes/mysql/8.0/en/news-8-0-0.html
- JSON:
CHECKSUM TABLEcalculated the checksums forJSONvalues using the memory addresses of the values rather than the values themselves, which made the checksum vary. Now in such cases the calculation is based on the actualJSONvalue, and not on that value’s address. (Bug #23535703)
- JSON:
python을 사용해 특정단위수의 row를 불러와 비교하는것으로 해결
banksalad의 사용법과 함께 작성해본 좌충우돌 AWS DMS 사용기 – feat. RDS 통합 이야기에서 1,000개 단위로 Row를 Sampling하고 Source와 Target에 대한 Row Diff x 만족할 때 까지 반복 부분이 우리와 같은 문제점이지 않을까.. 하는 추측
실질적인 체크 스크립트는 gpt와 이야기하면 잘 짜주므로 생략
6.4. File diff 비교
복제용 클러스터는 실 트래픽을 핸들링하는 서버가 아니기에 큰 서버스펙을 부여할 필요가 없다. 그렇지만 위의 checksum / Row data를 조회하는것은 서버 부하를 주기 때문에 실행시간이 길어진다는 문제점이 있다.
database에 저장된 값을 불러와서 조회하는 것은 성능/네트워크 상 병목이 생길 수 있기에, 각 저장된 덤프파일을 생성해 파일기반으로 비교또한 가능하다.
다만 테이블별로 용량이 크다면, 비교를 수행하는 머신에서 파일이 memory에 올라가지 못할 수 있다. 생성된 dump파일을 line 기반으로 분할하여 비교하여 동일성을 확인할수 있다.
split-compare.sh
- 비교가 필요한 두 대상 클러스터의 테이블의 덤프는 생성되었다고 가정
- split-compare.sh
#!/bin/bash
# nohup ./split-compare.sh > split-compare.log 2>&1 &
# 원본 파일
file1="compare-m.sql"
file2="compare-s.sql"
# 분할 파일 저장 경로
split_dir="split_compare"
# 분할 크기 설정 (1G/100Line)
# 용량 단위로 나눌 경우, 시작부분의 host 정보등에 따라 변경발생 가능, 라인 기반으로 나누는것이 안정적
#split_size=1G
split_line=1000
# 분할 디렉토리 생성
mkdir -p "$split_dir"
# 파일 분할
# split -b "$split_size" "$file1" "$split_dir/part_m_"
# split -b "$split_size" "$file2" "$split_dir/part_s_"
split -l "$split_line" "$file1" "$split_dir/part_m_"
split -l "$split_line" "$file2" "$split_dir/part_s_"
# 분할된 파일 개수 확인
parts_m=( "$split_dir"/part_m_* )
parts_s=( "$split_dir"/part_s_* )
# 분할된 파일 비교
echo "Comparing split files..."
for i in "${!parts_m[@]}"; do
if [[ -f "${parts_s[$i]}" ]]; then
echo "Comparing ${parts_m[$i]} with ${parts_s[$i]}"
diff "${parts_m[$i]}" "${parts_s[$i]}" > "$split_dir/diff_part_$i.txt"
if [[ $? -eq 0 ]]; then
echo "No differences in part $i"
else
echo "Differences found in part $i (saved to diff_part_$i.txt)"
diff "${parts_m[$i]}" "${parts_s[$i]}"
fi
else
echo "Missing corresponding part for ${parts_m[$i]}"
fi
done
echo "Comparison completed."결과 예시
- diff_part_0.txt (시작 부분)
# cat split_compare/diff_part_0.txt
[a@a split_compare]# cat diff_part_0.txt
3c3
< -- Host: testdb.logonme.click Database: testdb
---
> -- Host: localhost Database: testdb
5c5
< -- Server version 5.7.xx
---
> -- Server version 5.7.xx- diff_part_x.txt (끝 부분)
# cat split_compare/diff_part_x.txt
[a@a split_compare]# cat diff_part_x.txt
676c676
< -- Dump completed on 2025-01-01 11:11:11
---
> -- Dump completed on 2025-01-01 12:22:227. Outro
전체 서비스를 중단하여 트래픽 인입을 막은 뒤, 덤프 생성하고 복원하는 것은 긴 시간이 걸린다. 데이터베이스의 규모에 따라 다르겠지만 여파를 생각하면 최소 하루 ~ 길게는 달 단위로 중단을 걸어야할 수도 있고, 진행단계 중간에 지장이 걸린다면 재시도 및 완료까지 얼마나 시간이 걸릴지 짐작할 수 없다
- 다시 처음부터 수행해야지 뭐
- 덤프 생성 도중 스토리지 용량 이슈로 멈춘다면?
- 덤프 전달 도중 네트워크 이슈로 끊긴다면?
- 덤프 복원 도중 메모리 이슈로 멈춘다면?
위의 복제 및 CDC 기반으로 수행할 경우 실제 운영 DB는 계속 동작을 유지한 상태에서, 중간 단계를 분리 및 재시도가 가능해진다는 장점이 있다. 따라서 실제 중단시간 또한 유의미하게 감소시킬 수 있다.
ProxySQL 아쉬움
작업 레퍼런스를 찾던 도중, 해결하려는 목적이 유사하면서도 클러스터간에 proxy 레이어를 추가하여 완전한 중지없이 무중단으로 진행한 레퍼런스를 발견하였다. https://leezzangmin.tistory.com/68
그러나 proxoySQL은 활용하던 스택이 아니였고 작업전에 변수를 추가할 수 없기에 적용해보지는 못했지만.. 대용량 데이터베이스를 완전 무중단으로 전환할 수 있다고?는 꼭 다음에 기회가 있을때 한번 수행해보고 싶다. 두근두근 생각만해도 재밌겠다
- JVM에서 추가설정이없다면 30초에 한번 DNS resolve
- ProxySQL을 적용했을 경우 기존 코드/로직에 영향이 없을까?